This is the blog section. It has two categories: News and Releases.
Files in these directories will be listed in reverse chronological order.
This is the multi-page printable view of this section. Click here to print.
This is the blog section. It has two categories: News and Releases.
Files in these directories will be listed in reverse chronological order.
We are making up some lag and bringing Maveniverse site online. Stay tuned for updated content.
The Maveniverse Mason 0.1.0 is on Central!
To use it with Maven 4, add snippet below to .mvn/extensions.xml or ~/.m2/extensions.xml:
<extension>
<groupId>eu.maveniverse.maven.mason</groupId>
<artifactId>mason</artifactId>
<version>0.1.0</version>
</extension>
This blog entry was done as a response to Pom-Pom-Pom. Note: this entry does not want to be hurting, personal or anything like that; still my native language is not english, so bear with me (and feel free to create updates to it).
By reading that article, I frankly have no idea where to start. Take the title for example: “Brief history of POM proliferation”, and the article has nothing about it at all. So let me fill in, as history is important.
Around end of 2005., when Maven “as we know it today” (Maven 2.0) was born, in fact two things happened: not only the
Maven CLI (the command line utility that performs the build), but also Maven Central was born too
(true, not in today’s form), the venerable repo1.maven.org. One was envisioned with another, and one cannot exist
(or would be severely crippled, or dysfunctional) without the other. And this is the real strength of the Maven:
the idea of remote repository. Maven Central was created by Maven for Maven, as part of Maven as whole. It was
initially ran by one person (!), then a group of people, and finally since 2010s by Sonatype, as it is run today.
Maven today is kinda split-brain: the Java CLI part is maintained by volunteers only in their free time (or hobby time)
as part of ASF top level project, while the Maven Central, as mentioned above, is maintained by Sonatype.
Important to note: nobody pays for using Maven Central, it is a public good, with all the good and bad parts of it.
Fast-forward seven years, for first GA version of Gradle (2012), a commercially backed build tool to appear, that sat on the bandwagon with many other Java related tools, and consume Maven Central. As at that time, Maven Central was already de-facto the standard for OSS Java library distribution. Other tools learned (or tried to learn) to use it, and some, like Gradle even extended it with extra metadata (am unsure is any other tool using that extra metadata).
In short, Maven Central was created as part of Maven project, hence is a “Maven thing”, and together with CLI both have a history spanning over almost quarter of century. Knowing this, one could really expect it to be “all about POMs”. And you can imagine, during these years, we had always been approached by people or organizations coming to us (I was Sonatype in sonatype for almost 10 years) claiming they “know things better” or having better ideas or better solutions. But, here we are where we are.
Maven historically had a very convoluted and not-much-saying description, something along these lines: “Maven is a software project management and comprehension tool”. But let’s just focus on it’s “build tool” facet, and for sake of simplicity, ignore all its other aspects like “site building” etc.
While Maven is primarily used in Java projects (“Java build tool”), it can do more. In fact, Maven had many “native”
plugins, that did or did not survive until present. But in its core, the "java" is just one identifier for artifact
language, and Maven always supported other languages as well (native C/C++, Flex or even .NET).
Maven is a highly pluggable beast, in fact its “core” is really, really simple: it is just like an executor; you put your nibbles (plugin executions) on threads (lifecycle), and pack those into blocks (modules) and you have your reactor. Reactor can be executed linearly (single threaded) or there are different executors like Takari Smart Builder or Maven Turbo Builder that even rearranges your “nibbles” for better performance (with some sane restrictions).
Finally, the strength of Maven is declarative nature: you say what you want, and not how to do it (like Prolog vs Pascal). And yes, Maven has downsides, many, but none of them can become as hard to solve as solving spaghetti build scripts or Ant build XMLs. You always want to keep it simple (stupid), and if you do it, Maven will be your friend.
I always smile when people say “Maven is dead”, as it always reminds me of people doing same to Java. Java is “dead” for quite some time, according to some, just that it is not: we have constantly improving Java releases. And same thing happens with Maven: in fact, currently it is very vibrant community with its ups and downs, as every community driven project can be, where there are no “managers”, “roadmaps” and “budget” in question.
Right now, the “stable” Maven 3.9.x line is getting new releases and improvements, while Maven 4.0.x is heavily in the works, getting close to its GA. Maven 4.0.x line, due Maven 3 backward compatibility, cannot disrupt a lot (as it must support Maven 3 plugins and work with most of the existing builds out there), but is about to get first class support for JPMS among many other things.
The biggest problem of Maven today is simple: lack of resources. And due lack of resources, Maven suffers from:
And we cannot sort all of these, and many more issues in one go (plus, we should also work on Maven 4 codebase). On related note, even Maven 3.9.x line got myriad of improvements, that were never properly communicated by us.
Any help is warmly welcome and appreciated!
To find it out, wait for part 2. This above was only very brief history of POM file “proliferation”.
Just to remind people about Mimir, and why they want to use it: if you remember the Never Say Never blog entry diagram:
sequenceDiagram autoNumber Session->>Session: lookup Session->>Local Repositories: lookup Session->>Remote Repositories: lookup
With Mimir on board, it changes to this:
sequenceDiagram autoNumber Session->>Session: lookup Session->>Local Repositories: lookup Session->>Mimir Cache: lookup Mimir Cache->>Remote Repositories: lookup and cache
This means, that nuking local repository is not an impediment anymore, as you still have everything in your Mimir cache, and building is as fast as with populated local repository.
Just an advice: when using Maven 3 (and 4) you do want to make sure Central is always first remote repository
Maven would “consult”. Just add following snippet(s) to your user-wide settings.xml:
<profiles>
<profile>
<id>oss-development</id>
<repositories>
<repository>
<id>central</id>
<url>https://repo.maven.apache.org/maven2/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>central</id>
<url>https://repo.maven.apache.org/maven2/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</profile>
</profiles>
<activeProfiles>
<activeProfile>oss-development</activeProfile>
</activeProfiles>
With this in your user with Maven settings, Maven will take care to keep Central first.
By default, Maven kees Remote Repositories ordered (like in a POM, it obeys the order), but globally, they are assembled like this:
This implies, that IF you are building a project whose POM contains even one repository stanza (and not having env like that above) that is not Central, the POM defined repository will take precedence over Central. And many times, this is NOT what you want.
Things like itr option or using Maven RRF
would be next things to consider.
This article represents my own stance, and should not be taken as any kind of “rule”.
People tend to go for simplest solutions, and that is okay. Still, that is many times not quite feasible.
As an awkward example, that is completely viable: you may want to use Maven 4.0.x to build a Maven 3 plugin (why not?). But this is raising several questions, one of them is how to test the built plugin? Assuming you want to support Maven 3 with built plugin, it has to be Java 8 level. Using Maven 4 to run directly ITs for Java 8 is not doable, as Maven 4 requires Java 17 at runtime.
If you go for “simplest” way, by throwing matrix onto ./mvnw clean install -P run-its this will not allow you give full Java coverage. In other words, if you do this, it implies that your whole stack must be capable to work in your whole test matrix (like Java 8 or older and ancient Maven versions like 3.6), and this is many times not the case).
This was simple while Java was “slow”, and it was mostly about Java 7 or 8, but today, when Maven 3 specifies Java 8 baseline, but current LTS is soon Java 25, the envelope is stretching far too broader than before.
This also may imply that “good old” way of doing things, like just stick something to parent POM that building, testing or publishing (but only one of them) requires, may not work anymore.
For me, typical set is like:
As one can see, “build”, “test” and “publishing” poses wildly different requirements. Expecting that whole your stack fits the widest (test) matrix is just unreal.
This article assumes reader has basic knowledge about Maven, POM and related things. The main point is to offer high level conceptualization and explain things “why’s” and “why not”, and finally explain why you don’t want to listen to folks that tells you “never do…” (unless they are your parents).
This article is mostly about Maven 3, but mentions Maven 4 as well.
In Maven you will read about following very important things:
Let’s start from end.
This one is I think simplest, and also the oldest concept in Maven: Maven will get you all dependencies you need to build the project, like the ones you specified in POM. And to do so, Maven needs to know all remote repositories where required artifacts reside. In “ideal” situation, you don’t need to do anything: all your dependencies will be found on Maven Central.
By default, Maven will go over remote repositories “in defined order” (see effective POM what that order is) in a “ordered” (from first to last) fashion to get an artifact. This has several consequences: you usually want most often used repository as first, and to get artifacts from last repository, you will need to wait for “not found” from all repositories before it. The solution for first problem is most probably solved by Maven itself, having Maven Central defined as first repository (but you can redefine this order). The solution to last problem (and many more!) is offered as Remote Repository Filtering.
From time to time, it is warmly recommended (or to do this on a CI) to have a build “from the scratch”, like a fresh
checkout in a new environment, with empty local repositories. This usually immediately shows issues about artifact availability.
Nothing special needed here, usually is enough just to use -Dmaven.repo.local=some/alt/loca/repo to achieve this.
Also, from this above follows why Maven Repository Manager (MRM) group/virtual repositories are inherently bad thing:
By using them, Maven completely loses concept of “artifact origin”, and origin knowledge is shifted to MRM.
This may be not a problem for project being built exclusively in controlled environments (where MRM is always available),
but in general is very bad practice: In such environment if Maven users and MRM admins become disconnected, or just
a simple configuration mishap happens (by adding some new repository to a group) problems can arise: from suddenly much more artifacts becoming available
to Maven through these “super repositories” to complete build halt. And worse, Maven builds like these are not portable, as they have a split-brain situation:
to be able to build such a project, Maven alone is not enough! One need to provide very same “super repository” as
well. It is much better to declare remote repositories in POM, and have them “mirrored” (one by one) in
company-wide settings.xml, instead to do it opposite: where one have “Uber Repository” set as mirrorOf: * and points
it to a “super repository”. In former case Maven still can build project if taken out of MRM environment (assuming all
POM specified repositories are accessible repositories), while in latter case, build is doomed to simply fail when
no custom settings.xml and no MRM present. Ideally, a Maven build is portable, and if one uses group/virtual
repositories, you not only lose Maven origin awareness, but also portability. Hence, in case of using “super groups”,
MRM becomes Single Point of Failure, as if you loose MRM due any reason, all your builds are doomed to be halted/fail,
for as long MRM is not recovered and not set up in very same way as it was before. You are always in better situation,
if you have a “B plan” that works, especially if having one is really “cheap” (technically).
Remote repositories are by nature “global”, but the meaning of “global” may mean different thing in open source and “corporate” environments.
Remote repositories contains deployed artifacts meant to be shared with other projects.
Maven always had “local repository”: a local directory where Maven caches remotely fetched artifacts and installs locally built artifacts. It is obvious, that local repository is a “mixed bag”, and this must be considered when setting up caching on CI. Most of the time you want cached artifacts only, not the installed ones.
Since Maven 3.0, local repository caching was enhanced by “origin tracking”, to help you keep your sanity with “works for me” like issues. Cached artifacts are tracked by “origin” (remote repository ID), and unlike in Maven 2, where artifact (file) presence automatically meant “is available”, in Maven 3.0+ it is “available” only if artifact (file) is present, and origin remote repository (from where it was cached) is contained in caller context provided remote repositories.
Since Maven 3.9 users may specify multiple local repositories as a list of directories, where HEAD of the list is the local repository in its classic sense: HEAD receives newly cached and installed artifacts, while TAIL (list second and remaining directories) are used only for lookups, are used in read-only manner. This comes handy in some more complex CI or testing setups.
Since Maven 3.9 users may opt to use “split local repository” that solves most of the above-mentioned issues, and allows one to selectively delete accumulated artifacts: yes, you do want to delete installed and remotely cached snapshots from time to time. Luckily, “split local repository” keeps things in separated directories, and one can easily choose what to delete. But all this comes at a price: “split local repository” is not quite compatible with all the stuff present in (mostly legacy) bits of Maven 3 universe. Using “split local repository” is warmly recommended, if possible. If you cannot use it, you should follow advice from previous paragraphs, and nuke your local repository regularly, unless you want to face “works for me” (or the opposite) conflicts with CI or colleagues.
Local repositories are, as name suggests “local” to host (workstation or CI) that runs Maven, and is usually on OS local filesystem.
Local repositories contains cached artifacts pulled from remote repositories, and installed artifacts
that were built locally (on the host). You can also install-file if you need an artifact present in local repository.
Split local repositories keeps artifacts physically separated, while the default one keeps them mixed, all together.
Projects are usually versioned in some SCM and usually contain one or more subprojects, that again contain sources that when built, will end up as artifacts. So, unlike above, in remote and local repositories, here, we as starting point have no artifacts. Artifacts are materialized during build.
Still, inter-project dependencies are expressed in very same manner as dependencies coming from remote repositories. And given they are “materialized during build”, this has severe implications that sometimes offers surprises as well.
The session contains projects that Maven effectively builds: usually or most commonly is same as “Project” above,
unless some “limiting” options are used like -r, -rf or -N and alike. It is important to keep this (not obvious)
distinction, as even if checkout of the project contains certain module, if that module is not part of the Session,
Maven treats it as “external” (to the session). Or in other words, even if “thing is on my disk” (checked out), Maven
if told so, will treat it as external artifact (not part of Session).
How does Maven finds artifacts? Maven building may be envisioned as “onion” like structure, where search is performed from “inside to out” direction. Each artifact coordinate (GAV, that is “artifact coordinates” and has more elements than 3, but for brevity we consistently use “GAV” to denote artifact coordinates) is looked up in this order:
sequenceDiagram autoNumber Session->>Session: lookup Session->>Local Repositories: lookup Session->>Remote Repositories: lookup
In short, when Maven is looking up some artifact, it will start in session, if not found then in local repositories, and finally if still not found it will try to get it from remote repositories. Each “actor” except for Session may deal (and usually is) with multiple actual repositories. As mentioned above, Local Repositories may be a list of directories (lookup with iterate thru all of them in list order), and Remote Repositories also may contain several remote repository definitions as well. But in “most basic” case, user have one local repository and Maven Central as remote repository.
When we say artifact is resolvable, we mean that required artifact can be retrieved by one of the lookup calls.
If a required artifact is non-resolvable, build failure is the expected outcome.
Also, as can be seen, “limited Maven sessions” (when you narrow subprojects being built by any means) still must
have existing inter-subproject dependencies resolvable. Given you are narrowing the session, you must make sure this is fulfilled
as well. Easiest way to do it is by installing, as then locally built artifacts becomes available across multiple sessions
(Maven CLI invocations) by being present in Local Repositories. This does not pose any problem when rebuilding, as you
can see in call diagram, artifact if present in both places, in this example in Session and Local Repositories,
Session is asked first (“wins” over right hand ones).
You do want to install, to keep things simple. People advising “do not install!” usually justify their decision by some colloquial “beliefs” like “I don’t want to pollute my local repository”. That justification is a red herring as can be seen above: this implies that these people are married to their local repositories. They insist on keeping “pristine” something that is part of “planned maintenance”. This justification is just wrong, or, it may reflect those users confusion what Local Repositories are about. Local repositories are almost the same the part of project(s) you are working on, like checkouts. They are “within your work context”, not outside.
One of the praised new Maven 4 feature is -r resumption option, that makes you able that in case of, for example, Unit
Test failure, “fix the UT and continue from where you failed”, and it works without invoking install. Well, the truth
is that this is achieved by adding a new Maven 4 feature: project wide local repository (as opposed to user wide
local repository, as known in Maven 3). The praised feature works, in a way that Maven do installs after all, even if
you did not tell it to do so. So what gives?
Of course, this is not critique of a new, and a really handy feature, am just explaining what happens “behind the curtains”.
Moral of the story: you don’t want to keep your local repository pristine, you do want to make it “dirty” instead. “Polluting” (for me is funny even to think of this word, is like projects I work on are toxic) your Local Repository with artifacts from Project(s) you work on is part of normal workflow and process. And Maven 4 installs (true, not into local repository, but does it matter?) even if you don’t tell it to do so. Hence, you can calmly do the same thing while using Maven 3 and just following the “best practices” explained here and elsewhere. Again, flushing caches is part of planned maintenance.
Installing is also needed, in case you work on a chain of projects, that depend on each other. And example can be Maven and Resolver: if there is a bug, that needs Resolver code changes, there is no other ways than installing one and building another, that picks up fixed and installed artifacts from Local Repositories (to be honest, there are, but you don’t want to do what my fencing teacher told: “reach your left hand pocket with your right hand”… well, you can, but why would you?).
Ultimately, it is up to developer (the Maven user, but same stands for CI script as well) that needs to be “aware”, and just make sure that build works and produces what it needs to produce, of course by proper uses of caches and proxies to not bash publicly available Remote Repositories. If “by chance” a year-old installed SNAPSHOT ends up in your build, you have more problems as well; it just means you lack some healthy maintenance routine. No magic nor any kind of “silver bullet” will do this for you.
But as can be seen, depending on what you do, the “resolvable artifacts” should be resolvable. Hence, the simplest thing to do is always to “level up” them: from Session to Local Repositories by installing them (making them resolvable workstation-wide) or, deploying them to Remote Repositories (making them resolvable globally, if needed). Again, it all depends on what you do.
Snapshot Artifacts are yet another not well understood kind of artifacts, but now will mention them only in context of this blog. Best practice with them is to not let them “cross organizational boundaries”. Or in other words, within a company, one team is okay to consume snapshots of other team (boundary is “within a company”) assuming regular snapshot deployment is solved. Same stands for example for Apache Maven project: Maven depending on snapshot Resolver is okay (and even happens from time to time), given both are authored by us. In short, consumer should be able to influence the publishing of snapshots. You should never depend on snapshot that is outside your “circle of boundary”, which is hard to precisely define, but the smaller the circle is, the better.
On the other hand, when Maven does depend on snapshot Resolver, anyone building it will pull a snapshot artifacts and cache them to their local repository. And here is the thing: once, in the future, that codebase will get released and deployed to some remote repository (Resolver to Maven Central).
So what happens to that snapshot in your local repository? By default, nothing, but if you consider “server side” of things, MRM used by Apache foundation will clean it up, once released. This even more increases your “disconnect” from the reality: you have something cached that does not exist anymore.
Hence, snapshots are yet another reason why you want to nuke your local repository. They are not inherently bad either, but they do need some extra caution.
Below are some personal advices; you don’t have to do these like it, my idea is just to give some advices and explain why they matter.
For start, keep your OS and tools up to date. That stands for Java, SCM like git tools and of course for Maven as well.
There are many “meta” tools to maintain up-to-date developer tools on workstations, just make use of them.
For start, as many of us, I tend to work on my “daily job” projects (paid job) but also on “open source” stuff, many
times hopping from one to another. For start, I keep these environments separate, as best practice (but also by a must,
as paid job requires MRM access via dead slow VPN. Still, even if no VPN needed, I’d still keep the two separate).
This means I have two settings-XXX.xml and two Local Repositories (none in default location). The Maven settings ~/.m2/settings.xml file
is just a symlink to the one in use, to the “real” I work in: “work” or “oss”. Keeping unrelated things separated (compare
this to “keep ONE thing pristine/un-polluted”) is best practice.
An interesting side effect of this setup is that it is dead simple to detect some Maven or Plugin bug: if “default local repository” appears, I immediately know there is something in the build that does not play by the rules.
Next step assumes use of proper caches. You (and your CI jobs) do use them, right? I use Mímir on all my workstations (as user-wide extension, as I use mainly Maven 4 to develop). On the other hand, many of projects I build are “not yet ready” for things like Split Local Repository, hence I just nuke my local repository weekly or bi-weekly. Monday morning usually starts with nuking them (🤞).
I tend to project hop a lot, as I usually not work only on Apache Maven projects, but my PRs span from Quarkus, JBang, and Netty all over to Maveniverse, and all of those are built (and installed) on almost all of my workstations I hop from and to.
In further text, I will discuss my “oss” routines.
I tend to work on forked repositories using git, and remotes are usually called origin (my fork) and upstream (the
forked upstream repository). To pick up possible changes, what I do is (assuming I am on default branch, otherwise assume
git checkout master):
$ git fetch -p # fetches my fork; showing newly-created + updated + dropped branches; as I workstation-hop
$ git branch -D dropped # (optional; perform local cleanup of gone branches)
$ git fetch upstream -p # fetch upstream; same thing
$ git rebase upstream/master # (optional) pick up changes if any
$ git push origin main # (optional) if above happened, push changes to my fork for sync reasons
I repeat these steps as very first thing on projects I plan to work on (for example Maven and Resolver). This makes sure my local environment is synced with all the rest of teammates. If you are about to continue to work on a feature branch, this these steps above shall be repeated with feature branch, potentially (YMMV) merging in upstream master changes and pushing it to your fork and so on. Again, I do this as I do workstation-hop a lot, and my fork may contains changes I do on other workstation.
$ git clean -nfdx # local checkout cleanup; for example after Guillaume reshuffles modules in project
This command is “dry run” (due -n), but is handy to show how “dirty” your checkout is compared to git tracked
files and directories. If you actually need cleanup, remove the -n and invoke it.
This is like morning routine, and many times a must, when you work on several (inter dependant) projects. In fact, many
“real world” projects (Camel, Quarkus) offer some sort of “quick build” possibilities. As we all know -DskipTests is
bad thing, so what I do is usually:
$ mvn clean install -Dtest=void -Dsurefire.failIfNoSpecifiedTests=false
This is my “quick build” for Maven and Resolver (and all the other Apache Maven projects). A remark: our “work” project
has this configured by default on Surefire plugin, so just -Dtest=void (or any string that does not match test) is needed.
This way I know my local repository is “primed” (or populated on Mondays).
From this moment, one can open IDE or whatever and begin working on project. From here, if you work on single project,
you can continue issuing mvn verify or whatever you want.
Again, this depends on what you do: if you change to some feature branch that is “close to” master, no cleanup needed
but “quick build” is advised. In “big change” cases (compare Maven maven-3.9.x and
master branches!), a full git cleanup and “quick build” is advised.
If you are lucky, and you are able to use split local repository, you can find more tips under “Use Cases”.
Doing these “routines” should not take longer than having your first cup of coffee, while just like coffee does for you, it “warms up” Maven environment for real work. Of course, nothing is black or white: the mentioned projects like Camel and Quarkus may “quick build” for 20-30 minutes as well. In those cases, you will probably consider some other techniques like Maven Build Cache and others.
I am lucky to spend my time on “small scale” projects like Maven and Resolver are.
No, mvn clean install is not “pure evil”, it has its own merit. And no, installing built artifacts is not “polluting”,
that is really silly thing to say. And finally, if your build picks up a year ago installed SNAPSHOT from your local
repository, you are simply lacking proper and planned maintenance. Snapshot cleanups is what usually modern MRMs do
on scheduled basis, same should happen to your local repository. Don’t feel pressured to submit yourself to “facts”
that are more like “beliefs”, and as such, are usually wrong. That said, it is much better to get accustomed and learn
what and how your tools do, instead to become a blind “cult follower”.
Join to Maven Users list and feel free to ask!
This text was inspired by following presentation and things mentioned in it, like the funny memes. I do recommend you to watch it, is very informative, while IMHO at some points makes wrong conclusions! Based on this presentation I decided to add my “share” of fun: memes. These are freely reusable, if you want to post them anywhere. Generated by https://imgflip.com/memegenerator.




Maven4 is coming, so it may be time to explain some of the changes it will bring on.
I’d like to start from “user facing” end, the mvn command and what has changed
(visible and invisible changes).
In short, Maven3 has a well known mvn (and mvn.cmd Windows counterpart) script in place
that users invoke. This script observed some of the environment variables (think MAVEN_OPTS
and others), observed mavenrc file, tried to find .mvn directory and also load .mvn/jvm.config
from it, if existed, and finally, it fired up Java calling
ClassWorlds launcher
class and setting the launcher configuration to conf/m2.conf file.
From this point on, the ClassWorlds launcher populated the classloader(s) following
the instructions in the configuration file, and finally invoked the “enhanced” main
method of the configured main class, that was maven-embedder:org.apache.maven.cli.MavenCli.
This is how MavenCli received the (preconfigured) ClassWorld instance.
The MavenCli class then parsed arguments, collected Maven system and user properties, built
“effective” settings (from various user and installation settings.xml files), created
DI container, while loading any possible build extension from .mvn/extensions.xml, if present,
then populating MavenExecutionRequest, looked up Maven component, and finally invoked it
with the populated request. And this is where “Maven as you know it” started.
The subproject maven-embedder is frozen and deprecated. It still works, but offers
“legacy” face (like no new Maven4 options support and alike).
We faced several problems with this setup. For start, there was a lot of scaffolding around to
invoke just one executable: mvn. The whole thing was not extensible, it had many things
“bolted on” and finally it was not reusable. But let’s start in order.
Maven3 introduced “password encryption” (that it had issues on its own, but that is another
story). The CLI options to handle those actions were in fact “bolted on” to MavenCli, that
“semi booted” Maven (kinda, but not fully), and all this only to perform those actions without
DI or anything helpful. This was akin (and comments in source were suggesting this as well)
for a separate tool to handle password encryption. We knew we need more “Maven tools”, as
mvn alone is not enough. The mvnenc tool handling password encryption in Maven4 is first
of these. One example of what Maven3 is unable to handle: Plexus Sec Dispatcher was always
“extensible” with regard of Ciphers. Idea was to add it as extension. But alas, to have that
new Cipher picked up, you’d need DI (and load extensions), so without DI all this never worked.
Moreover, the MavenCli was mish-mash of some static methods, making it not extensible nor reusable.
This was really evident and most painful bit in new Maven Daemon (and biggest obstacle to make it
“keep up” with Maven) The Maven Daemon was forced to copy-pasta it, and then modify this class,
to make it work for mvnd use case. And as expected, this lead to ton of burden to maintain and “port”
changes from Maven CLI to mvnd CLI. We knew this situation is bad, and we wanted to reuse most if not all
of Maven CLI related code in mvnd. Essentially, they both do the “same thing”, just latter
“daemonize” Maven.
There were the ITs as well: the Maven ITs were not able to test new Maven4 features (like new
CLI options) as ITs historically used Maven Verifier, that either executed Maven in forked
process (read: was slow) or used “embedded” mode, that again went directly into
MavenCli “tricky method”. It was not justified to fork any IT that wanted to use new
Maven 4 CLI options.
Finally, the state of the MavenCli was quite horrible, frankly. Few of us dared to enter
that jungle. Was very-very easy to mess up things in there, and moreover, have those issues
become known only after release, as Verifier “trick method” did not catch it.
I don’t want to go into details, so on high level these are the changes:
mvn script got “parameterizable main class”, and this made possible simple introduction
of alternative scripts, like mvnenc, that simply sets alternate main class, while everything
else remains same and everything else is reused.m2.conf observes this “main class” and launches accordingly.MavenCLI class).The CLIng module resides in impl/maven-cli and the idea is simple this:
String[] args (and other sources) are parsed chosen by Parser into InvokerRequestInvoker executes the parsed InvokerRequestInvoker#invoker(Parser#parse(args))That’s really the high level picture. CLIng itself is “layered” in a sense of different
requirements per layer. Various Parsers support various CLI options, so parsers are layered
as:
BaseParser parses “common” Maven-tool optionsMavenParser extends BaseParser and parses “mvn” CLI optionsThe idea is that all these “specialization” build upon previous layer, in this case
BaseParser, that is the common ground: options supported by all Maven CLI tools (not just mvn).
For execution, similar thing happen, it is layered as this:
LookupInvoker - abstract, handles “base” things, like user and system properties, DI creation along with
extension loading and all. This is the common ground of new Maven CLI tools, gives out of the
box properly configured logging, DI (with extensions loaded) and all the groundwork.MavenInvoker - abstract, extends LookupInvoker and does “mvn specific things”EncryptInvoker - extends LookupInvoker and does “mvnenc specific things”In short: “lookup” provides the “base ground” (that mvn and other tools like mvnenc)
build upon. Again. goal is to have in all tools shared support for “common” features
(think -X logging, or -e show stack traces, etc.).
Furthermore, MavenInvoker (an abstract class) has two “specializations” that are non-abstract:
LocalMavenInvoker - This invokes Maven “locally”, expects to have all the Maven on classpath. This ismvn. It does all the needed things as explained
above, just lookup Maven component and invoke it with pre-populated MavenExecutionRequest.
This invoker is “one off”, in a sense, it creates DI and all the fluff, executes,
and then tears everything down.ResidentMavenInvoker - A specialization that makes Maven “resident”. On first call
happens all the creation of DI and all the fluff, tear down is prevented at execution end,
and subsequent incoming InvokerRequest is executed by already created, “resident” Maven.
One important note: DI and extension loading happens only once (very first call), hence not
all “resident instances” are same! The logic of routing, which request may be executed
by which resident instance" is in fact implemented in Maven Daemon, as mvnd keeps a “pool” of
Resident Maven processes. Also, Maven itself has a limitation that “one Maven instance may be
present in one single JVM” (due things like pushed System properties and others).
Resident Maven is cleaned up (properly shut down) when the resident invoker is closed.With these things in Maven “proper” we were able to achieve substantial “diet” in Maven Daemon,
where CLIng is really “just reused”. From that
PR, release of Maven and Maven Daemon can really happen “in sync” as latest rc-1 release
proved. Also, we got first tool in Maven Tools suite, the mvnenc.
Finally, for integration tests, we introduced impl/maven-executor module with similar design
as CLIng has. It is a dependency-less library that is reusable and is amalgam of good old
maven-verifier and maven-invoker but do the job less intrusive and in a future-proof way.
Maven Executor has 4 key bits:
mvn).The Maven Integration Tests already contained own “extended Verifier” instance that extended
the old maven-verifier Verifier class. The redirection happened in maven-it-helper
“extended Verifier”, by dropping maven-verifier and maven-shared-utils dependencies,
and introducing maven-executor instead. Very few ITs were harmed in this process.
Maven is well known for flexible configurability. Many times, those configuration and setting
files can contain sensitive data (like passwords). Long time ago, it was even common practice
to put gpg.passphrase in POM properties! The latest GPG plugin releases introduced
bestPractice parameter, that when enabled, prevents getting the GPG passphrase in
“insecure” ways. Furthermore, new versions of GPG plugin will flip the default value
and finally remove all the related parameters (see MGPG-146
for details).
But GPG is not the only thing requiring “sensitive data”. There are things like server passwords,
and many other things, that are usually stored in settings.xml servers section, but also
proxy passwords and so on.
Maven3 introduced Password encryption that was introduced as “the solution”, but technically it was very suboptimal.
Maven4 will change radically in this area. For start, Maven4 will rework many areas of “sensitive data” handling, and it will be not backward compatible with Maven3 solution, while Maven4 will support “obfuscated” Maven3 passwords (at the price of nagging user).
Maven3 password encryption, without going into details, had several serious issues, In fact, we call it “password obfuscation” as by design, it seemed more close to it. Problems in short:
Cipher used to encrypt was flawed - as explained in this PR that also fixed it. But alas, the fix was not backward compatible, it would require all the Maven3 uses would be forced to re-encrypt their passwords, and moreover, it would still not solve the fundamental issue.
“Turtles all the way down”: Maven3
password encryption encrypt server passwords using “master password”. And where was master
password? On disk. Ok, and how was “master password” protected? Well, it was encrypted in
very same way as server passwords, using “master-master-password”. You see where it goes?
Given “master-master-password” is well-known (will leave it as homework for figure it out),
this “encryption” was really just an “obfuscation”. Whoever got access to your
.m2/settings-security.xml was able to access all the rest as well.
Moreover, Maven3 worked in “lazy decrypt” way: it handled (potentially encrypted) sensitive data
as opaque strings, and “just at the point of use” tried to decrypt it (was a no-op if not encrypted)
and make use of it, for example in Resolver Auth. The idea was to “keep passwords safe” from
(rogue) plugins, that have plain access to settings, and would be able to steal it. But alas again,
same those (rogue) plugins had access to SettingsDecrypter as well (all is needed is to inject
it), and essentially they still had access to all sensitive data. This also caused strange,
and usually too late weird errors as well, like after 5 hours of building Maven could spit
“ERROR: I chewed through all your tests, and now would like to deploy, but cannot decrypt
your stale password; please rinse and repeat”. It was never obvious who is to blame here,
stale encrypted password, and simply wrong credentials.
Maven4 got fully redone encryption, while it does support Maven3 setup at the cost of nagging: it will warn you that you have “unsafe” passwords in your environment.
Moreover, Maven4 does eager decryption: at boot it will strive to decrypt all encrypted strings (ah yes, it decrypts all, so even your HTTP headers carrying PT token as well!), and will fail to boot if it fails even on one. Your path forward is to clean up your environment from stale and/or broken encrypted passwords. Maven4 “security boundary” is JVM process, and if you think about it, same thing happened in Maven3, as explained above. The difference is that Maven3 forced on every plugin the burden of decryption, that plus had its own issues (remember the MNG-4384 and how all the plugins were forced to carry their “own” PlexusSecDispatcher component?). Also, you have to be aware, that encryption applies to settings only. So in POM you should not have any sensitive data, no matter is it encrypted or plaintext.
Second, the Cipher used for encryption is completely reworked and improved. Also, passwords are now “future-proof” encoded in a way one can upgrade them safely to a new Cipher.
Finally, turtles are gone. Just like it happened in GPG plugin, Maven4 does not store any “master password” anymore. What it has instead, is “Master Password Source” that can be variety of things. Maven4 offers 5 sources out of the box, but those are extensible.
Sources are:
pinentry executablegpg-agent executableHence, Maven4 will always try to get the master password from your configured source.
On CI you can make it a “secret” and pass over via environment variable, while on workstation
you can (and should) hook it into pinentry or gpg-agent that usually provide integrations
with host OS keychains as well.
Maven4 password encryption is handled by the new CLI tool: mvnenc.
From Maven perspective, whether a component is defined as Plexus component (via Plexus XML, crafted manually or during build
with plexus-component-metadata Maven Plugin) or JSR330 component, does not matter.
But there is a subtle difference.
Plexus components store their “definition” in XML that is usually embedded in JAR, so Plexus DI has not much to do aside to parse the XML and use Java usual means to instantiate it, populates/wires up requirements and publish it.
Very similar thing happens with JSR330 defined components, but with one important difference: JSR330
components are discovered via “sisu index” (there are other means as well like classpath scanning, but for performance
reasons in Maven only the “sisu index” is used), a file usually embedded in JAR at META-INF/sisu/javax.inject.Named file.
The index file contains FQCN of component classes. So to say, “data contents” of Sisu index is way less than that of Plexus
XML. Hence, Sisu at runtime has to gather some intel about the component.
To achieve that, Sisu uses ASM library to “lightly introspect” the component, and once all the intel collected, it instantiates it, populates/wires up requirements and publishes it.
But the use of ASM has a huge implication: the components bytecode. While in case of “Plexus defined” components all the “intel” is in XML, and the component bytecode needs to be supported only by the JVM component is about to reside, in case of Sisu, things are a bit different: to successfully introspect it, the component bytecode has to be supported by ASM library used by Sisu (also, Guice uses ASM as well).
Table of Maven baseline versions and related upper boundaries of supported Java bytecodes.
| Maven baseline | Java baseline | org.eclipse.sisu version | ASM version | Java bytecode supported by ASM |
|---|---|---|---|---|
| 3.6.x | 7 | 0.3.3 | 5.x (shaded) | Java 8 (52) |
| 3.8.x | 7 | 0.3.3 | 5.x (shaded) | Java 8 (52) |
| 3.9.x | 8 | 0.3.5 | modded 5.x for Java 14 (shaded) | Java 14 (58) |
| 3.9.6 | 8 | 0.9.0.M2 | 9.4 (shaded) (*) | Java 20 (64) |
| 3.9.8 | 8 | 0.9.0.M3 | 9.7 (shaded) | Java 23 (67) |
| 4.0.x | 17 | 0.9.0.M3 | 9.7 (not shaded) (**) | Java 23 (67) |
(*) - recent versions of Guice (since 4.0) and Sisu (since 0.9.0.M2) releases offer “no asm” artifacts as well, along with those that still shade ASM in.
(**) - Maven 4 uses “no asm” artifacts of Guice and Sisu and itself controls the ASM version included in Maven Core, to be used by these libraries.
Maven3 on the other hand, continues to use shaded one, as before.
This has the following implications: if you develop Maven Plugin, Maven Extension, and your project contains JSR330 components, and you claim support for:
The problem is, that Sisu will silently swallow issues related to “not able to glean” the component (due unsupported
bytecode version). To see these, you can use -Dsisu.debug.
Hence, the ideal thing you can do, if you develop Plugins or Extensions that declare “minimum supported Maven version” is to also compile to that bytecode level as well. Otherwise, you must pay attention and follow this table.
On related node, recent Sisu versions introduced this flag: https://github.com/eclipse-sisu/sisu-project/pull/98 Also, latest Maven 4.0.x comes with this flag enabled.
PS: Just to be clear, do NOT go back to Plexus XML. Plexus allows only default constructor for start (hence, have much simpler job to do). Sisu “introspection” is really minimal, is figuring out which constructor needs to be bound, and if one still uses field injection, which those fields are.
PPS: This above is true only for “pure JSR330” components, it does not stand for Maven Plugins.
Enjoy!
Here am trying to explain what is Maveniverse/MIMA, but also to explain what it is not.
There is Maven, as we know it, and there are libraries that Maven uses to be “Maven as we know it”, like
Resolver is. Many times, use case requires use of “Resolver only”
without all the fuss and fluff of Maven. Historically, there was the ServiceLocator, that made Resolver
somewhat reusable outside of Maven, but then MRESOLVER-157
came in, so what now?
ServiceLocator was conceived in “Plexus DI” times, and implied several shortcomings most importantly
“no constructor injection”, so we really had to get rid of it. Also, even if one used it, the “user experience”
was near zero: you still had to solve interpretation of user environment (like settings.xml, password encryption, etc).
Basically, everyone had to redo everything, as can be seen from the amount of “copy-paste” code across all the
projects reusing Maven Resolver. Resolver did get a “replacement” for deprecated (and removed in 2.x) ServiceLocator
in form of MRESOLVER-387 but just like ServiceLocator,
this one offered same level of “user experience”. Same problems existed still.
Moreover, Maven 3.9.x itself (for various reasons) prevents you from creating “own” (embedded) Resolver instance inside of it, that is, when you run embedded in Maven as a Maven Plugin or Build or Core extension. All Maven versions offered you its own Resolver, just inject it!
Resolver itself may look like a respectable code base, but it is
incomplete. Resolver was envisioned as “generic” and “reusable”, hence Resolver itself does not
contain any traces of “models”, as in reading “metadata”, discovering “versions” and so on. In fact, to make
Resolver complete, you must implement several components of it, that are not implemented in Resolver itself.
Resolver alone is incomplete even at object graph level (lacking implementations). To “complete” Resolver, Maven implements the missing components
in maven-resolver-provider
subproject, but alas, this subproject depends on maven-model-builder
subproject, as one can expect, Resolver to interpret POMs, needs fully built (and profile activated) models,
even if Resolver itself never even touches POMs/Maven Models. Resolver have no idea about the syntax nor the
real contents of Maven POM.
Maven roughly, very roughly looks like this, where “Artifacts” block should be more like “Artifact Collection, Resolution, Transport (and more)”.
block-beta columns 8 Maven:8 Classloading:2 DI:2 Projects:2 Artifacts:2 Classworlds:2 Sisu:2 ProjectBuilder ModelBuilder:2 Resolver
Again, roughly the “Classloading” deals with classpath isolations of Maven Core, Extensions, Plugins and Projects, for more see here. The “DI” block is dealing with Dependency Injection. The “Projects” deals with “your POMs”, and building (or whatever you do) of them. Finally, the “Artifacts” block deals with, well, “Artifacts” (external ones but also yours as well, once built, like installing or deploying them). Maveniverse MIMA covers the lower right side of this diagram, basically the “Artifacts” only. Do notice though, that “ModelBuilder” is shared between “Projects” and “Artifacts”.
The “MIni MAven” project was conceived when I realized how all the existing solutions to “reuse Maven Resolver” were incomplete, or “non-aligned” at least. When I went over some of the most notable users of Resolver, like JBoss Shrinkwrap Resolver, Ops4J Pax URL and JBang (just to mention some of the major ones) and to figure out that same code, even if not dully copied and pasted, but clearly the intent was very the same, is repeated over and over again, with all of their own bugs, shortcomings, “not yet implemented” and everything as one can expect.
Goals of MIMA are following:
settings.xml, decrypt passwords if needed, etc.In general, MIMA wants to be more like “Man in Black”, present but not seen (am alluding to movie if anyone have any doubts), but instead of aliens, it deals with providing you “full Resolver experience” whether you run “embedded in Maven” (ie Maven Plugin or Extension) or “standalone” (outside of Maven).
MIMA allows you to code like this:
ContextOverrides overrides = ContextOverrides.create().build();
try (Context context = Runtimes.INSTANCE.getRuntime().create(overrides)) {
... use ResolverSystem and ResolverSystemSession from Context
}
It basically offers you pretty much the same experience whether you run “embedded” in Maven or “standalone” in CLI.
MIMA merely tries to “hide” from you from where RepositorySystem and RepositorySystemSession comes from. From Maven?
Or did MIMA just create one for you? Don’t care about it.
In any case, it allows unfettered access to Resolver APIs. Also, important to mention, MIMA offers Resolver access “up to maven-core”.
That above means a difference as well: for example packaging plugins are not injected when using MIMA in standalone
mode (as that part of Model Builder is done by components that reside in maven-core). But again, MIMA offers
Resolver APIs, that is about Artifacts and not about building of theirs. If you want building, use Maven.
Despite the name, MIMA is not Maven, is just a piece of it.
About Maven 4, MIMA and the future, we still have to see how things fit together. But just to drive your fantasies, here are listed few possibilities:
maven-resolver-provider (and deps) => this is MIMA 2.xmaven-resolver-provider (and deps, thanks to binary compatibility) => Theoretically could work, but who would need this?A small fable for myself and others…
The Takari Polyglot Maven 0.7.1 was released not so long ago, and it contained one trivial change, this pull request. The goal was to fix following issue: JRuby folks had some problem, that could be solved among other ways, by creating a “custom JRuby Polyglot Maven distribution” (see related pull request).
But, while testing this, I came to strange conclusion: the Polyglot extension did work when loaded up through
.mvn/extensions.xml, but did not work when loaded up from core (when it was added to lib/ext of custom
Maven distribution). Fix seemed simple, raised the priority of TeslaModelProcessor and done. Polyglot started
working when in lib/ext, so I released 0.7.1.
But then, as you can see from first PR long comment thread, a bug report flew in from none else then Eclipse Tycho.
So what happened? And how comes Plexus in the story?
Historically, Plexus DI addresses components by role and roleHint. Originally, and this is important bit, both,
the role and roleHint were plain string labels:
Object lookup(String role);
Object lookup(String role, String roleHint);
Later, when Java 1.5 came with generics, Plexus got the handy new method:
<T> T lookup(Class<T> klazz);
<T> T lookup(Class<T> klazz, String roleHint);
And it made things great, no need to cast! But under the hood, labels were still only labels. You made them explicit either
via components.xml that accepted the role and roleHint or via annotations like this
@Component(role=Component.class, roleHint="my")
public class MyComponent implements Component {}
You explicitly stated here: “class ComponentImpl is keyed by role=Component.class and roleHint='my'”. One thing
you could not do in Plexus, is to reach for implementation directly: there was no role MyComponent.class!
@Requirement
private MyComponent component;
So far good. But in Eclipse Sisu on other hand things are slightly different and many times overlooked. Sisu uses Guice JIT/implicit bindings generated on the fly. This means that Sisu can infer many of these things by just doing this:
@Singleton
@Named("my")
public class MyComponent implements Component {}
And this component can be injected into series of places: those wanting Component but also those wanting MyComponent.
So Sisu can do, wile Plexus DI cannot, is to make injection happen like this:
@Inject
private MyComponent component;
Why is that? As Sisu figures out effective type of injection point and then matches the published ones with it. But this has also some drawbacks as well… especially if you cannot keep things simple. And how comes Polyglot here? Well, Maven Core, for sure is not kept simple. The original problem was this implementation:
@Singleton
@Named
public class TeslaModelProcessor implements ModelProcessor {}
But wait a second, how does ModelProcessor look like? Oh, it looks like this:
public interface ModelProcessor extends ModelLocator, ModelReader {}
And there are components published implementing ModelLocator and
ModelReader as well! Basically, ModelProcessor
implementation can be injected into spots needing ModelLocator or ModelReader as well (as they are type
compatible)!
And the fix? Well, as one can assume, to “restrict” the type of the component.
But, the @Typed annotation comes with some implications as well…
Great “literature” to skim over:
Remember: you are completely fine as long you keep things simple. The fact you see one interface does not mean you have one role! You need to look into hierarchy as well. While moving from Plexus DI to JSR330, this is one of the keystones to keep in mind.
Enjoy!
As weird as title sounds, given Maven 4 is “around the corner”, the sad reality is that there are still way too many libraries and plugins in “Maven ecosystem” that rely on some sort of “compatibility” layers (and deprecated things) in Maven 3. For example Eclipse Sisu is fully functional and in charge since Maven 3.1.0 (released in 2013, when last missing piece, support for “sisu index” was added). Maven project during it’s existence did pile up some of the debts, or in other words, “moved past” some well known libraries. Plexus DI Container and Wagon being the most notable examples.
The Plexus DI Container is from the Plexus umbrella project that started on great
Codehaus (and do smile while you read this).
Plexus project consists of many subprojects: the
“die hard” plexus-utils, Plexus DI container, Plexus Compilers, Plexus Interactivity, and so on, and so on.
But let’s focus on Plexus DI.
When I joined Sonatype in 2007., we started “porting” the Proximity from Spring DI 1.x to Plexus DI to make Nexus 1.0. While we were porting it, more and more issues cropped up with Plexus Container, that mostly stemmed from the vastly different use case for it: at that point, Plexus DI was mostly used as container for Maven (mvnd was nowhere yet!), a one-time CLI that started up, discovered, created and wired up components, did the build, and then JVM exited. It was a big contrast in use case, Nexus was meant to be a long-running web application. We started fixing and improving Plexus, but then stepped in Stuart, and he made Sisu happen. Sisu was a suite, or layers of DI, that built upon then “brand new” Guice, and it added a “shim” layer on top of it, that implemented the “Plexus layer”. In short, Sisu builds upon Guice, and Plexus-shim builds upon Sisu. All the giants in a row.
The goal of Plexus-shim was to provide a true “drop in replacement” for old plexus-container-default, and funnily
enough, Nexus 1.x project served as “functional test ground”. The reason for that was Plexus DI never had any TCK or
similar test suite. Basically, all we had was some existing codebases (Maven, Nexus) with their own suite of functional
and integration tests, and codebase used plexus-container-default. So we then just built the project with swapped out
Plexus DI (using Plexus-shim instead) and ran same test suite again. Rinse and repeat. It was fun times.
The original Plexus DI was great at the time (mid 2000s), but new DI solutions surpassed it. Biggest problem with Plexus DI was that all it “knew” was field injection that, among other things, made writing UTs a bit problematic. Since modern DIs, we all know that “constructor injection” is the way, but it never happened in Plexus DI. The implication was that libraries using Plexus DI (that to be frank, was mostly around and in “Maven ecosystem”) could not write immutable components or proper unit tests (am not saying it was not possible, but was more a burden than it should have been).
My childhood fencing trainer had a saying: “is like reaching to your left pocket with right hand”. Same feeling was about Plexus DI when Guice barged in. We desperately needed something better, and Sisu DI made that happen.
As I mentioned above, since Maven 3.1 Sisu is “fully functional” in Maven. Still, most likely due inertia, many projects left unchanged, even Maven “core” ones, and remained in a cozy state: why change, if everything works? Sure, that is merely the proof of great job Stuart did back then.
Around early 2021. frustration of several Maven PMCs resulted in creating a “cleanup manifesto” to simply stop postponing the inevitable, as Maven codebase almost came to the grinding halt: no progress or innovation was possible, as whatever we touched, the other pile broke. Moreover, the “future of Maven” was way too long in the air. The heck, even I had a presentation in 2014. called “The Life and Death of Apache Maven” (in Hungarian). Ideas like “new POM model” and many other things were left floating around for way too long.
Just let me repeat, the “de-plexus” notion is heavily emphasized in that “cleanup manifesto” document, for a good reason.
Maven 4 will come with its own API (more about it in some later post), but one fact stands: the Maven DI (new in 4) resembles the JSR330, not the Plexus DI (with all the XML and stuff).
Basically, just do yourself a favor, and move from Plexus DI to JSR330 now. You will thank me later.
I’d just like to throw in a short explanation how (IMHO) should organize CI jobs for simple Maven projects for better and faster turnaround.
People usually “throw up a matrix” and just run mvn verify -P run-its. Sure, that is really the simplest.
But what if, our matrix is big? Or what if we want to utilize one of the Maven basics, the Local repository?
I wanted to mimic what I do locally: I usually build/install with latest stable Maven (3.9.9 currently) and latest LTS Java (21.0.4 currently), and then perform a series of ITs/test/assessments, to ensure the thing I build covers all combos of Maven/Java/whatever.
First example is Maveniverse/MIMA: It is a Java 8 library, and covers
compatibility of Java [8,) and Maven [3.6.3,), hence it does have a
huge matrix.
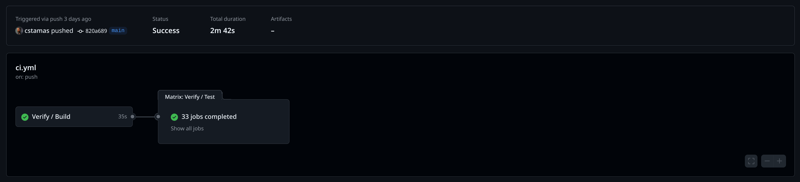
33 jobs Matrix.
Screenshot: Tamas Cservenak / CC-BY-CA
But the build is organized in “two phases”, like build once, and test built thing multiple times (instead to “rebuild it over and over again and run tests on rebuilt thing”). The first job builds and installs the library into local repository, then matrix comes with reused local repo cache, hence what was built and installed in there, is available and resolvable for subsequent jobs, where the tests runs only.
Second example: Maveniverse/Toolbox: It is a Java 21 Maven 3 Plugin,
covers compatibility of Java [21,) and Maven [3.6.3,), a bit smaller matrix.
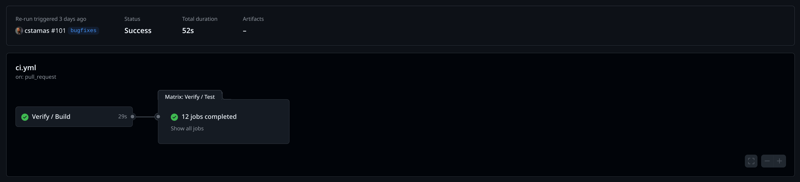
12 jobs Matrix.
Screenshot: Tamas Cservenak / CC-BY-CA
Again, same story: first job builds and installs using Maven 3.9.9 + Java 21 LTS, then matrix comes to play to ensure Maven 3.6.3 - Maven 4.0.0 all works with it (and only one dimension for Java, the 21 LTS). For this to work, we’d never want to collocate plugin ITs (ie invoker) and plugin code itself in same subproject, but is better to keep them in separate subprojects (in my case is added with profile run-its).
All in all, build only ONCE and test what you BUILT many times! Enjoy.
Ever repeating question from plugin/extension developers is “how to add new packaging” (in a “modern way”).
For ages we did it by manually crafting plexus.xml in the plugin or extension JAR, that was not only error-prone
but also tedious. But, indeed it had a great value as one could easily filter the XML (ie filtering plugin versions).
But, plexus XML is plexus XML… yuck. So what now?
Here is an example from Eclipse Tycho: The tycho-maven-plugin originally defined this Plexus XML (and yes, it did
filter for versions as well):
<component-set>
<components>
<component>
<role>org.apache.maven.lifecycle.mapping.LifecycleMapping</role>
<role-hint>p2-installable-unit</role-hint>
<implementation>
org.apache.maven.lifecycle.mapping.DefaultLifecycleMapping
</implementation>
<configuration>
<lifecycles>
<lifecycle>
<id>default</id>
<phases>
<validate>
org.eclipse.tycho:tycho-packaging-plugin:${project.version}:build-qualifier,
org.eclipse.tycho:tycho-packaging-plugin:${project.version}:validate-id,
org.eclipse.tycho:tycho-packaging-plugin:${project.version}:validate-version
</validate>
<initialize>
org.eclipse.tycho:target-platform-configuration:${project.version}:target-platform
</initialize>
<process-resources>
org.apache.maven.plugins:maven-resources-plugin:${resources-plugin.version}:resources
</process-resources>
<package>
org.eclipse.tycho:tycho-packaging-plugin:${project.version}:package-iu,
org.eclipse.tycho:tycho-p2-plugin:${project.version}:p2-metadata-default
</package>
<install>
org.apache.maven.plugins:maven-install-plugin:${install-plugin.version}:install,
org.eclipse.tycho:tycho-p2-plugin:${project.version}:update-local-index
</install>
<deploy>
org.apache.maven.plugins:maven-deploy-plugin:${deploy-plugin.version}:deploy
</deploy>
</phases>
</lifecycle>
</lifecycles>
</configuration>
</component>
</components>
</component-set>
So, how to migrate this off plexus XML?
We know Plexus XML “defines” components, managed by Plexus DI (and based by not so friendly Maven internal classes). Our goal would be then to create a JSR330 component. So, let’s create a “support class” first:
package org.eclipse.tycho.maven.lifecycle;
import java.io.IOException;
import java.io.InputStream;
import java.io.UncheckedIOException;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import org.apache.maven.lifecycle.mapping.Lifecycle;
import org.apache.maven.lifecycle.mapping.LifecycleMapping;
import org.apache.maven.lifecycle.mapping.LifecyclePhase;
import javax.inject.Provider;
public abstract class LifecycleMappingProviderSupport implements Provider<LifecycleMapping> {
private static final String DEFAULT_LIFECYCLE_KEY = "default";
private final Lifecycle defaultLifecycle;
private final LifecycleMapping lifecycleMapping;
public LifecycleMappingProviderSupport() {
this.defaultLifecycle = new Lifecycle();
this.defaultLifecycle.setId(DEFAULT_LIFECYCLE_KEY);
this.defaultLifecycle.setLifecyclePhases(loadMapping());
this.lifecycleMapping = new LifecycleMapping() {
@Override
public Map<String, Lifecycle> getLifecycles() {
return Collections.singletonMap(DEFAULT_LIFECYCLE_KEY, defaultLifecycle);
}
@Override
public List<String> getOptionalMojos(String lifecycle) {
return null;
}
@Override
public Map<String, String> getPhases(String lifecycle) {
if (DEFAULT_LIFECYCLE_KEY.equals(lifecycle)) {
return defaultLifecycle.getPhases();
} else {
return null;
}
}
};
}
private Map<String, LifecyclePhase> loadMapping() {
Properties properties = new Properties();
try (InputStream inputStream = getClass().getResourceAsStream(getClass().getSimpleName() + ".properties")) {
properties.load(inputStream);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
HashMap<String, LifecyclePhase> result = new HashMap<>();
for (String phase : properties.stringPropertyNames()) {
result.put(phase, new LifecyclePhase(properties.getProperty(phase)));
}
return result;
}
@Override
public LifecycleMapping get() {
return lifecycleMapping;
}
}
Using this support class, our actual mapping becomes “just” a simple empty class, that maps the component name (that is mapping name) onto data:
package org.eclipse.tycho.maven.plugin;
import org.eclipse.tycho.maven.lifecycle.LifecycleMappingProviderSupport;
import javax.inject.Named;
import javax.inject.Singleton;
@Singleton
@Named("p2-installable-unit")
public class P2InstallableUnitLifecycleMappingProvider extends LifecycleMappingProviderSupport {}
And we add the following Java Properties file to the same package where class above is. The “binary name” of
the properties file should be org/eclipse/tycho/maven/plugin/P2InstallableUnitLifecycleMappingProvider.properties:
validate=org.eclipse.tycho:tycho-packaging-plugin:${project.version}:build-qualifier,\
org.eclipse.tycho:tycho-packaging-plugin:${project.version}:validate-id,\
org.eclipse.tycho:tycho-packaging-plugin:${project.version}:validate-version
initialize=org.eclipse.tycho:target-platform-configuration:${project.version}:target-platform
process-resources=org.apache.maven.plugins:maven-resources-plugin:${resources-plugin.version}:resources
package=org.eclipse.tycho:tycho-packaging-plugin:${project.version}:package-iu,\
org.eclipse.tycho:tycho-p2-plugin:${project.version}:p2-metadata-default
install=org.apache.maven.plugins:maven-install-plugin:${install-plugin.version}:install,\
org.eclipse.tycho:tycho-p2-plugin:${project.version}:update-local-index
deploy=org.apache.maven.plugins:maven-deploy-plugin:${deploy-plugin.version}:deploy
And finally, all we need to do is to enable filtering on resources. And we have the very same effect as with huge Plexus XML.
To verify ourselves, just add a small UT, just to check the things:
package org.eclipse.tycho.maven.plugin;
import org.apache.maven.lifecycle.mapping.LifecycleMapping;
import org.apache.maven.lifecycle.mapping.LifecycleMojo;
import org.apache.maven.lifecycle.mapping.LifecyclePhase;
import org.eclipse.sisu.launch.Main;
import org.junit.jupiter.api.Test;
import javax.inject.Inject;
import javax.inject.Named;
import java.util.Map;
import static org.junit.jupiter.api.Assertions.assertEquals;
@Named
public class LifecycleMappingTest {
@Inject
private Map<String, LifecycleMapping> lifecycleMappings;
@Test
void smoke() {
LifecycleMappingTest self = Main.boot(LifecycleMappingTest.class);
assertEquals(7, self.lifecycleMappings.size());
System.out.println("All mappings defined in this plugin:");
for (Map.Entry<String, LifecycleMapping> mapping : self.lifecycleMappings.entrySet()) {
System.out.println("* " + mapping.getKey());
for (Map.Entry<String, LifecyclePhase> phases : mapping.getValue().getLifecycles().get("default").getLifecyclePhases().entrySet()) {
System.out.println(" " + phases.getKey());
for (LifecycleMojo mojo : phases.getValue().getMojos()) {
System.out.println(" -> " + mojo.getGoal());
}
}
}
}
}
Enjoy!